혹시나 해서 최종 자료말고는 내가 했던 사전 조사나 EDA, 분석 위주로 정리
주제는 최근 5년간 급격히 변한 서울 부동산 시장, 2030세대(영끌족) 중심
주제를 정하고 각자 주제에 대해 뭘 할 수 있을지 어떤 데이터를 구할 수 있을지 찾아보기로 함
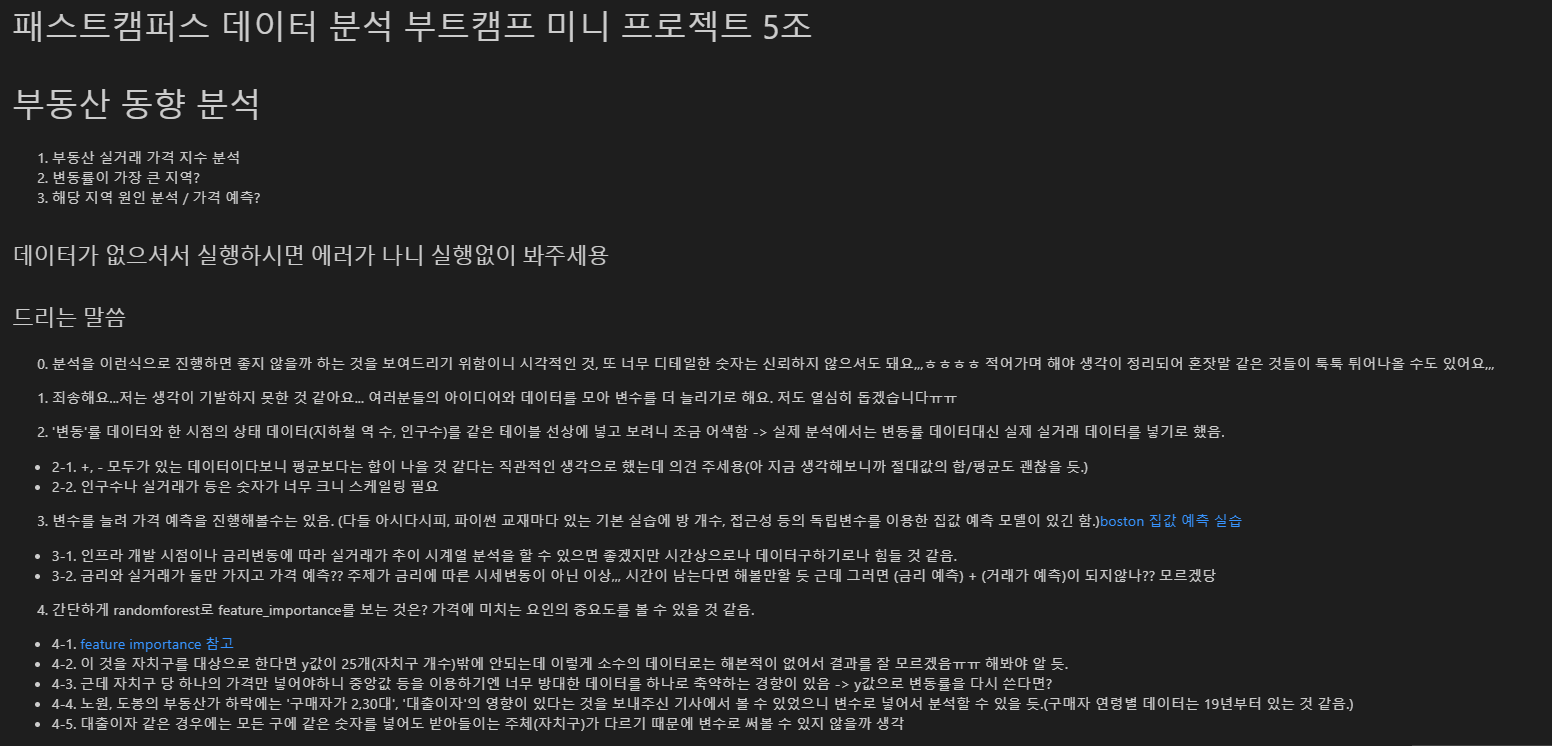
파일 공유할 때 넣어놓은 참고 메모
### 드리는 말씀
0. 분석을 이런식으로 진행하면 좋지 않을까 하는 것을 보여드리기 위함이니 시각적인 것, 또 너무 디테일한 숫자는 신뢰하지 않으셔도 돼요,,,ㅎㅎㅎㅎ 적어가며 해야 생각이 정리되어 혼잣말 같은 것들이 툭툭 튀어나올 수도 있어요,,,
1. 죄송해요...저는 생각이 기발하지 못한 것 같아요... 여러분들의 아이디어와 데이터를 모아 변수를 더 늘리기로 해요. 저도 열심히 돕겠습니다ㅠㅠ
2. '변동'률 데이터와 한 시점의 상태 데이터(지하철 역 수, 인구수)를 같은 테이블 선상에 넣고 보려니 조금 어색함 -> 실제 분석에서는 변동률 데이터대신 실제 실거래 데이터를 넣기로 했음.
- 2-1. +, - 모두가 있는 데이터이다보니 평균보다는 합이 나을 것 같다는 직관적인 생각으로 했는데 의견 주세용(아 지금 생각해보니까 절대값의 합/평균도 괜찮을 듯.)
- 2-2. 인구수나 실거래가 등은 숫자가 너무 크니 스케일링 필요
3. 변수를 늘려 가격 예측을 진행해볼수는 있음. (다들 아시다시피, 파이썬 교재마다 있는 기본 실습에 방 개수, 접근성 등의 독립변수를 이용한 집값 예측 모델이 있긴 함.)[boston 집값 예측 실습](https://wikidocs.net/49966)
- 3-1. 인프라 개발 시점이나 금리변동에 따라 실거래가 추이 시계열 분석을 할 수 있으면 좋겠지만 시간상으로나 데이터구하기로나 힘들 것 같음.
- 3-2. 금리와 실거래가 둘만 가지고 가격 예측?? 주제가 금리에 따른 시세변동이 아닌 이상,,, 시간이 남는다면 해볼만할 듯 근데 그러면 (금리 예측) + (거래가 예측)이 되지않나?? 모르겠당
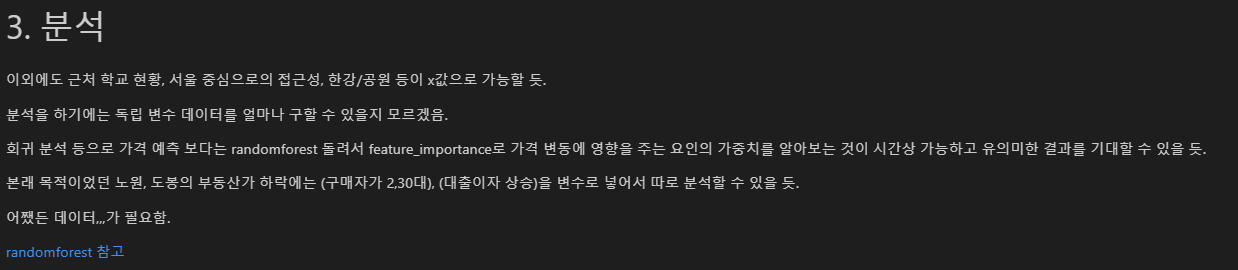
4. 간단하게 randomforest로 feature_importance를 보는 것은? 가격에 미치는 요인의 중요도를 볼 수 있을 것 같음.
- 4-1. [feature importance 참고](https://hongl.tistory.com/129)
- 4-2. 이 것을 자치구를 대상으로 한다면 y값이 25개(자치구 개수)밖에 안되는데 이렇게 소수의 데이터로는 해본적이 없어서 결과를 잘 모르겠음ㅠㅠ 해봐야 알 듯.
- 4-3. 근데 자치구 당 하나의 가격만 넣어야하니 중앙값 등을 이용하기엔 너무 방대한 데이터를 하나로 축약하는 경향이 있음 -> y값으로 변동률을 다시 쓴다면?
- 4-4. 노원, 도봉의 부동산가 하락에는 '구매자가 2,30대', '대출이자'의 영향이 있다는 것을 보내주신 기사에서 볼 수 있었으니 변수로 넣어서 분석할 수 있을 듯.(구매자 연령별 데이터는 19년부터 있는 것 같음.)
- 4-5. 대출이자 같은 경우에는 모든 구에 같은 숫자를 넣어도 받아들이는 주체(자치구)가 다르기 때문에 변수로 써볼 수 있지 않을까 생각
0. 사용한 모듈, 패키지, 기본 한글 세팅
import pandas as pd
import numpy as np
import copy
import datetime as dt
import seaborn as sns
import matplotlib.pyplot as plt
import matplotlib.font_manager as fm
font_path = 'C:\\Windows\\Fonts\\NanumBarunGothicLight.ttf'
font = fm.FontProperties(fname=font_path).get_name()
plt.rc('font', family='NanumBarunGothic')
pd.set_option('display.max_columns', None)
# pd.reset_option('display.max_columns')
1. 실거래 가격지수 변동률 확인
* 얘기 나눌 때 실거래가보다는 실거래 가격지수를 활용해보기로 했음
1-1. 실거래 가격지수 데이터 불러오기
한국통계정보시스템 - 한국부동산원 : 전국주택가격동향조사 월간 매매 가격지수
https://www.reb.or.kr/r-one/statistics/statisticsViewer.do?menuId=HOUSE_21211
부동산 통계 뷰어
세계 최고의 부동산시장 조사·관리 및 공시·통계 전문기관 통계별로 검색시간이 길어 질 수 있으며 “크롬” 브라우저를 이용하면 검색시간을 단축할 수 있습니다. Chrome 다운로드
www.reb.or.kr
# folder = 'C:\\Users\\Y\\Desktop\\데이터분석_미니프로젝트\\data\\부동산\\'
raw_df = pd.read_excel(folder + '월간_매매가격지수_종합_201801-202212_수정.xlsx', header=[0,1]) #, index_col=[0, 1])
raw_df
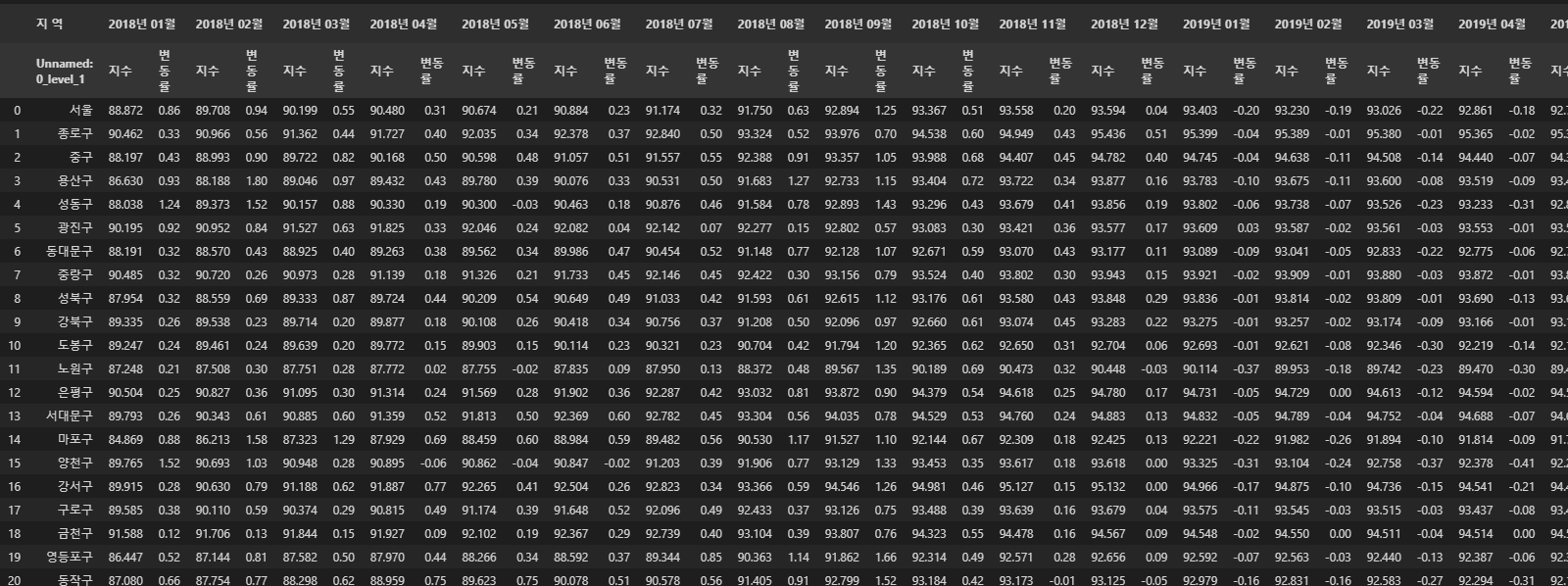
# 인덱스 처리 쉽게 하려고 행열 전환함
raw_df = raw_df.T
raw_df.rename(columns=raw_df.iloc[0], inplace=True)
raw_df = raw_df.drop(raw_df.index[0])
raw_df
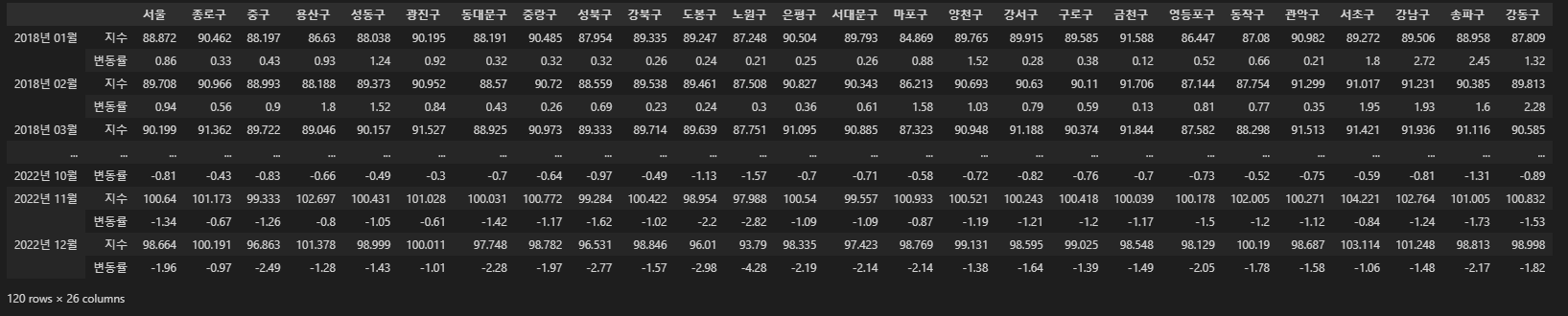
1-2. 데이터 타입 변환
# 전체 숫자값 타입이 object라 float으로 변환
raw_df = raw_df.astype(float)
raw_df.info()

1-3. 변동률만 필터링
멀티인덱스에서 원하는 인덱스만 추출하려면 xs 함수 사용
# 변동률만 보기
# multi_index(level_0:날짜, level_1:지수/변동률)
rate_df = raw_df.xs('변동률', level=1).T
rate_df

1-4. 변동률 합/평균
# 변동률 합
rate_df.sum(axis=1).sort_values()

# 변동률 평균
rate_df.mean(axis=1).sort_values()


1-5. 변동률 합 기초 통계값
rate_df.T.describe()

1-6. 추이 확인 위한 자치구, 연도별 변동률 합
# 자치구, 연도별 변동률 합
rate_sum_df = pd.DataFrame(rate_df.loc[:, '2018년 01월':'2018년 12월'].sum(axis=1), columns=['2018년 변동률 합'])
rate_sum_df = pd.concat([rate_sum_df, pd.DataFrame(rate_df.loc[:, '2019년 01월':'2019년 12월'].sum(axis=1), columns=['2019년 변동률 합'])], axis=1)
rate_sum_df = pd.concat([rate_sum_df, pd.DataFrame(rate_df.loc[:, '2020년 01월':'2020년 12월'].sum(axis=1), columns=['2020년 변동률 합'])], axis=1)
rate_sum_df = pd.concat([rate_sum_df, pd.DataFrame(rate_df.loc[:, '2021년 01월':'2021년 12월'].sum(axis=1), columns=['2021년 변동률 합'])], axis=1)
rate_sum_df = pd.concat([rate_sum_df, pd.DataFrame(rate_df.loc[:, '2022년 01월':'2022년 12월'].sum(axis=1), columns=['2022년 변동률 합'])], axis=1)
rate_sum_df = pd.concat([rate_sum_df, pd.DataFrame(rate_df.sum(axis=1), columns=['전체 변동률 합'])], axis=1)
rate_sum_df.sort_values('전체 변동률 합', ascending=False)

1-7. 변동률 추이 시각화
# 서울 전체 지수를 기준으로 서울 지수보다 낮은 자치구 대상으로 그래프 그림
chart_target = rate_sum_df[rate_sum_df['전체 변동률 합'] < rate_sum_df.loc['서울', '전체 변동률 합'] ]
# 그래프에서 '전체 변동률 합' 컬럼은 제외
target_col = chart_target.loc[:, chart_target.columns != '전체 변동률 합'].T
plt.figure(figsize=(15,8))
# palette = sns.color_palette('pastel6')
palette = sns.color_palette('dark')
sns.lineplot(target_col, palette=palette, legend=True)

1-8. 추후에 변동률 절대값으로도 해보긴 했음

# 변동률 절대값으로 진행
rate_abs_df = abs(rate_df)
# 자치구, 연도별 변동률 절대값 합
rate_abs_sum_df = pd.DataFrame(rate_abs_df.loc[:, '2018년 01월':'2018년 12월'].sum(axis=1), columns=['2018년 변동률 합'])
rate_abs_sum_df = pd.concat([rate_abs_sum_df, pd.DataFrame(rate_abs_df.loc[:, '2019년 01월':'2019년 12월'].sum(axis=1), columns=['2019년 변동률 합'])], axis=1)
rate_abs_sum_df = pd.concat([rate_abs_sum_df, pd.DataFrame(rate_abs_df.loc[:, '2020년 01월':'2020년 12월'].sum(axis=1), columns=['2020년 변동률 합'])], axis=1)
rate_abs_sum_df = pd.concat([rate_abs_sum_df, pd.DataFrame(rate_abs_df.loc[:, '2021년 01월':'2021년 12월'].sum(axis=1), columns=['2021년 변동률 합'])], axis=1)
rate_abs_sum_df = pd.concat([rate_abs_sum_df, pd.DataFrame(rate_abs_df.loc[:, '2022년 01월':'2022년 12월'].sum(axis=1), columns=['2022년 변동률 합'])], axis=1)
rate_abs_sum_df = pd.concat([rate_abs_sum_df, pd.DataFrame(rate_abs_df.sum(axis=1), columns=['전체 변동률 합'])], axis=1)
rate_abs_sum_df.sort_values('전체 변동률 합', ascending=False)

2. 부동산 가격 요인
2-1. 지하철역
2-1-0. 데이터 로드
공공데이터포털 - 국가철도공단 주소데이터 사용
https://www.data.go.kr/data/15041113/fileData.do
국가철도공단_코레일_지하철_주소데이터_20221122
코레일에서 관리하는 도시광역철도역들의 철도운영기관명, 선명, 역명, 지번주소, 도로명주소의 데이터가 있습니다.
www.data.go.kr
# 자치구별 지하철역 수 정리해놓은 데이터셋이 있긴했는데 숫자호선 데이터뿐이길래 따로 찾아서 정리함
# folder = 'C:\\Users\\Y\\Desktop\\데이터분석_미니프로젝트\\data\\지하철\\'
subway_tmp = pd.read_csv(folder + '국가철도공단_수도권_주소데이터.csv', header=0, encoding='cp949')
print(subway_tmp['선명'].unique())
subway_tmp.head()
2-1-1. 데이터 전처리
# 서울에 있는 지하철역만 필터링
subway_df = subway_tmp[subway_tmp['도로명주소'].str.contains('서울', na=False)]# info로 null값 여부 확인
# subway_df.info()
# null값 확인
subway_df[subway_df['역명'].isnull()]

# 동묘앞역
subway_df['역명'] = subway_df['역명'].fillna('동묘앞')
subway_df[subway_df['역명'] == '동묘앞']

# 사용할 컬럼만 분리하기
# subway_df.columns # Index(['철도운영기관명', '선명', '역명', '지번주소', '도로명주소'], dtype='object')
target_col = ['선명', '역명', '도로명주소']
subway_df = subway_df[target_col]
subway_df.head()

2-1-2. 도로명 주소에서 자치구 추출
# 도로명주소에서 자치구 슬라이싱
subway_df['자치구'] = subway_df['도로명주소'].str.split(' ').str[1]
del subway_df['도로명주소']
subway_df = pd.concat([subway_df, pd.read_csv(folder + '신분당선, 신림선_주소데이터.csv', header=0)]).reset_index(drop=True) # 신분당선, 신림선 데이터셋은 없길래 만들어서 넣음
subway_df.sample(10)
2-1-3. 자치구별 지하철역 수 카운트
sub_cnt_df = pd.DataFrame(subway_df['자치구'].value_counts()).rename(columns={'자치구':'지하철역 수'})
sub_cnt_df
2-1-4. 변동률 데이터프레임과 join
# rate_df에는 '서울'인덱스 있기 때문에 sub_cnt 기준으로 left join
sub_rate = sub_cnt_df.join(rate_sum_df, how='left')
sub_rate

2-2. 생활인구

2-2-0. 데이터 로드
서울 열린데이터 광장- 자치구 단위 서울 생활인구
https://data.seoul.go.kr/dataList/OA-15439/S/1/datasetView.do
열린데이터광장 메인
데이터분류,데이터검색,데이터활용
data.seoul.go.kr
# folder = 'C:\\Users\\Y\\Desktop\\데이터분석_미니프로젝트\\data\\인구\\'
# 실거래 데이터를 2022년까지 보기로 해서 20221231 기준 데이터 받아옴
pop_tmp = pd.read_csv(folder + '자치구단위 서울생활인구 일별 집계표.csv', header=0, encoding='cp949')
pop_tmp

pop_tmp = pop_tmp[['시군구명','총생활인구수']].set_index('시군구명').astype(int) #어차피 많은 사람,,,int로 소수점 날림,,,
pop_tmp

2-2-1. 변동률, 지하철역 수 데이터프레임과 join
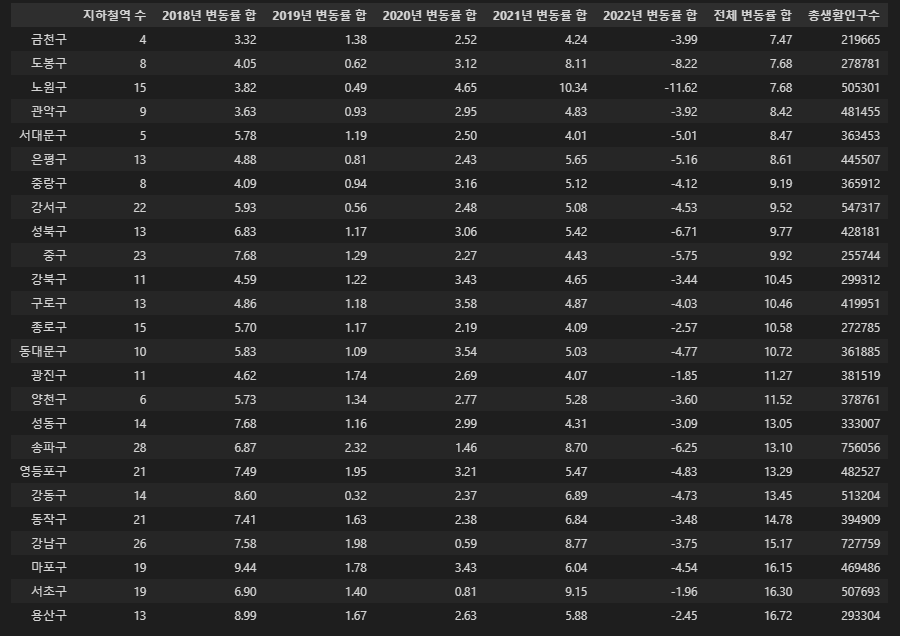
sub_pop_rate = sub_rate.join(pop_tmp, how='left').sort_values('전체 변동률 합')
sub_pop_rate
2-3. 매입자 연령대
2-3-0. 데이터 로드
한국부동산원 부동산통계정보시스템 - 부동산 거래현황 - 아파트매매 거래현황 - 월별 매입자연령대별
https://www.reb.or.kr/r-one/statistics/statisticsViewer.do?menuId=LHT_65010
부동산 통계 뷰어
세계 최고의 부동산시장 조사·관리 및 공시·통계 전문기관 통계별로 검색시간이 길어 질 수 있으며 “크롬” 브라우저를 이용하면 검색시간을 단축할 수 있습니다. Chrome 다운로드
www.reb.or.kr
# folder = 'C:\\Users\\Y\\Desktop\\데이터분석_미니프로젝트\\data\\인구\\'
age_df = pd.read_excel(folder + '월별_매입자연령대별_주택매매거래_동호수_201901-202212_수정.xlsx', header=0)
age_df
2-3-1. 노원구만
age_df[(age_df['지 역'] == '노원구') & (age_df['매입자연령대'] == '20대이하')]

3. 분석
'[패스트캠퍼스] 데이터분석부트캠프 > Python' 카테고리의 다른 글
| [7주차] Python: 데이터 분석 미니 프로젝트_EDA (1) | 2023.04.20 |
|---|---|
| [6주차] Python: 크롤링 (0) | 2023.03.31 |
| [5주차] Python: List (0) | 2023.03.23 |
| [5주차] Python: 제어문(if, elif, else) (0) | 2023.03.23 |
| [5주차] Python: 파이썬 데이터 타입, 변수 (0) | 2023.03.23 |